'취미/Technology'에 해당되는 글 12건
- 2026.01.26 안녕 Evernote
- 2022.10.19 [Matlab] 2D Gaussian Convolution
- 2022.02.23 Notion 입문 1달차
- 2022.02.03 tensorflow에서 시작하는 pytorch 작동 방식 (iris example)
- 2022.01.11 Notion 입문 1일차
- 2021.08.19 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) 3
- 2020.10.12 리튬계 베터리와 5V
- 2018.09.09 HC-08 블루투스 모듈 아두이노 연결 1
- 2018.08.24 Mendeley와 Cloud 같이 쓰기
- 2018.08.05 로지텍 헤드셋 G633 리뷰 및 수리기 17
초창기에 "클라우드"의 개념을 아무도 모르던 시절에 혜성같이 등장한 Evernote.
첫인상도, 쓰는 와중에도 계속 느껴왔던 것이지만, 클라우드 기능이 추가된 워드패드 그 이상도 이하도 아니라 미묘한 포지션이었습니다. 그래도 한 기기에서 작성한 노트를 다른 기기에서 바로 볼 수 있다는 것은 정말 혁신적이라고 생각했던 기억이 있어요. 기술에 대해 잘 모르시는 분들께도 Dropbox와 함께 '아, 이것이 클라우드라는 것이다'를 설명하기에 아주 좋은 예시였죠.
다양한 경쟁자가 등장했음에도 가격과 극도로 효율화된 동기화 기능 때문에 살아남은 Dropbox와 달리, 기존 기능을 거의 그대로 고수했던 Evernote는 하향길로 접어들었습니다. Bending Spoon에 인수된 뒤로 무언가 변화가 생길 줄 알았는데, 긍정적인 변화는 보기 어려웠습니다.
하긴, 단순한 노트앱으로는 사용자를 모으기가 너무 어려울 것 같고, 강력한 경쟁자인 Notion에 비해 더 나은 점도 없었어요.
한때는 몰스킨과 콜라보한 노트 제품을 사기 위해서 홍콩에 가기도 했었는데, 결국 무료버전에서는 접속 가능한 기기를 1대로 제한하는 것을 보고 탈퇴를 결심했습니다. 암호화 기능을 사용해서 일기를 쓰거나, web clipper를 자주 사용했는데 백업기능이 없기에 하루가 꼬박걸렸습니다. 저는 그래도 노트가 300개 남짓 있었는데 1000개가 넘어갔다면 그냥 정말 필요한 것만 빼고 다 지웠을 것 같네요.

'취미 > Technology' 카테고리의 다른 글
| [Matlab] 2D Gaussian Convolution (0) | 2022.10.19 |
|---|---|
| Notion 입문 1달차 (0) | 2022.02.23 |
| tensorflow에서 시작하는 pytorch 작동 방식 (iris example) (0) | 2022.02.03 |
| Notion 입문 1일차 (0) | 2022.01.11 |
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
2D Gaussian Convolution filter
2D space에서 image smoothing, noise 제거 등을 위해서 Gaussian filter를 적용할 때가 있다.
Matlab에는 워낙 다양한 toolbox들이 있어서 간혹 유사한 기능을 하는 함수들이 존재하기도 하는데, 때문에 같은 기능을 다양한 방식으로 구현을 할 수 있다.
오늘 imgaussfilt 함수와 mvnpdf 함수를 사용해서 Gaussian filter를 적용을 하다가 몇가지 차이점과 유의점을 발견하여 이곳에 적는다.
Original Image
코드 설명에 사용할 Original Image를 만드는 코드이다.
100 x 100 이미지에 (50, 50) 과 (20, 50) 의 pixel만 1의 값이 들어가있다.
originalImage = zeros(100,100);
originalImage(50, 50) = 1;
originalImage(20, 50) = 1;Method 1: imgaussfilt
함수 개발 목적 자체가 2D 이미지에 Gaussian filter를 적용하기 위한 것이기 때문에 가장 간단하게 원하는 목적을 달성할 수 있다.
figure(1);
clf;
sigma = 1;
fimage1 = imgaussfilt(originalImage, sigma, 'FilterSize', 101);
imagesc(fimage1);여기서 중요한 것은, 'FilterSize' Name-Value pair인데, 이 값을 입력하지 않거나, 작은 값으로 설정하는 경우 convolve 하는 kernel의 크기가 작아서 빠르지만 조금은 부정확한 결과가 나올 수 있다.
참고로 fimage1의 합은 2가 된다.
Method 2: mvnpdf로 kernel을 만든 뒤 conv2
직접 2D Gaussian kernel을 만든 뒤에 원본이미지와 conv2 함수를 사용해서 적용하는 방식이다.
[X,Y] = meshgrid(1:101, 1:101);
X = X(:);
Y = Y(:);
mu = 51;
sigma = [1, 0; 0, 1];
kernel = reshape(mvnpdf([X,Y],mu,sigma),101, 101);
fimage2 = conv2(originalImage, kernel, 'same');
figure(2);
imagesc(fimage2);51의 값은 101 크기의 kernel의 중간값이다.
위 결과는 imgaussfilt의 결과와 정확히 일치한다.
함수 개발 목적 자체가 2D 이미지에 Gaussian filter를 적용하기 위한 것이기 때문에 가장 간단하게 원하는 목적을 달성할 수 있다.
'취미 > Technology' 카테고리의 다른 글
| 안녕 Evernote (0) | 2026.01.26 |
|---|---|
| Notion 입문 1달차 (0) | 2022.02.23 |
| tensorflow에서 시작하는 pytorch 작동 방식 (iris example) (0) | 2022.02.03 |
| Notion 입문 1일차 (0) | 2022.01.11 |
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
Notion 입문 1일차
#스타트업 #힙스터 #팀워크 #생산성 스타트업'스러움'이 하나의 문화컨텐츠로 떠오르면서 온갖 제품과 서비스들이 이러한 분위기에 맞추어지고 있다. 마치 Helvetica 폰트가 디자이너들에게 사랑
blog.knowblesse.com
이전에 Notion을 하루 써보고 소감을 간략히 적어봤었는데 이제 사용을 시작한지 한달이 되었다. 지금쯤이면 평이 달라지지 않았을까.
장점
1. Markup
이 기능이 생각보다 편리하다. [ / ]버튼 하나로 각종 형식들을 만들 수 있고 evernote에 비하면 적은 노력을 들이고도 읽기 편한 문서를 만들 수 있다는 점이 가장 큰 강점으로 작용한다. 사실 낙서를 포함하는 자유도가 높은 메모는 실제 종이에서 하는 것이 가장 좋다. 디지털화가 필요한 문서의 경우 어느정도 구조화된 아이디어인 경우가 많은데 evernote는 이를 표현하기에는 '동기화가 가능한 메모장'에 지나지 않았다. Notion은 이 '구조화된 아이디어'를 정리하기에 정말 적합한 서비스이다.

2. Page 구조
이것은 Notion의 장점이라기 보다는 OneNote가 구현해내지 못한 단점에 가까울까. OneNote도 hierarchical 구조를 가지고 있기는 하다만 제한적인 depth를 가지고 있고 최상위 객체인 전자 필기장이 로딩이 느리다는 인상을 자주 받는다. 그에 비해서 Notion은 무한히 Page를 확장할 수 있고, 가볍다는 것이 확실히 느껴진다.

단점
1. Spell check
아니 Spell check가 제대로 안된다는게 있을 수 있는 일인가. 어째서인지 내 환경에서는 spell check 기능이 작동하지 않고 turn on/off 메뉴도 나타나지 않는다. 그리고 공식 설명에 따르면 setting page에 따로 spell check 기능 관련 메뉴가 없다던데 이 부분은 정말 아쉽다. 아쉬운대로 Grammarly 의 윈도우 add-on을 사용하고 있는데 이 부분은 시급히 개선해야할 것 같다.
2. Keyboard Shortcut
한컴오피스에 익숙한 한국인이라 그런지 키보드 단축키의 부족함을 느낀다. 다른 앱들도 별반 다를 것이 없겠다만 이러한 기능도 구현이 되었으면 하는 아쉬움이 남는다.
총평
사용 1일차에 느꼈던 감상과 다르지 않다.
'이렇게 참신하고 대단한게 나오다니!' 보다는 '이런게 왜 이제야?'에 가깝다.
사실 노트 작성 프로그램이 '참신하다'라는 평을 받을 가능성이 거의 없음을 감안하면 최고의 평가가 아니었나 싶다. Vim 정도 되면 악랄함을 포함한 참신성을 느낄 수 있겠다만 글쓰고 동기화 시켜주는 에디터에 더 바랄게 뭐가 있으랴. 전반적으로 크게 불편함을 느끼는 부분이 존재하지 않고, 깔끔하게 완성되는 output이 흡족함을 준다. 무엇보다 notion을 쓰면서 evernote가 괘씸해졌다. 초반의 무료정책에 반하게 점점 가격이 올라가고 기능은 변하지 않는 모습에 결국 Notion 사용 한달차에 올 8월까지 결제가 되어있는 유료 플랜을 해지했다. Notion도 이제 시장에 진입한 초기 서비스라 나중에 결제 플랜이 어떻게 바뀔지는 모르겠으나 지금 수준의 가격만 유지된다면 사용료 때문이라도 이쪽으로 넘어올 가치가 충분히 있는 것 같다.
'취미 > Technology' 카테고리의 다른 글
| 안녕 Evernote (0) | 2026.01.26 |
|---|---|
| [Matlab] 2D Gaussian Convolution (0) | 2022.10.19 |
| tensorflow에서 시작하는 pytorch 작동 방식 (iris example) (0) | 2022.02.03 |
| Notion 입문 1일차 (0) | 2022.01.11 |
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
Intro
협업하는 팀의 사정으로 원래 쓰던 tensorflow를 놔두고 pytorch로 갈아타게 되었다. 때문에 포스트의 제목이 이런 식이다.
사실 tf v1 때는 변수 만드는 방법부터 배워야 할 정도로 사용성이 아주 부족했는데 keras의 등장 및 v2에서의 편입 이후로 레토르트 식품 데우듯이 쉽게 ML 모델 개발이 가능해졌다. 이러나 저러나 복잡한 모델을 만들지 않는 이상tensorflow와 pytorch 모두 주인장에게는 cuda를 편하게 쓰게 해주는 도구에 지나지 않고 이쯤 시간이 흘렀으면 사용성이 엇비슷하지 않을까 하는 생각에 1시간 정도 걸리리라 생각했다.
당장 튜토리얼부터 마음에 안들었다.

동영상 자료는 재끼고, Basic에는 대뜸 Tensor 설명부터, Example에는 간단한 Iris, MNIST는 있지도 않다. 그나마 있는 example은 Image Classification. numpy랑 연동이 잘 된다고 하기엔 받아먹는 data형 제한이 너무 귀찮았고 (Linear function은 float32가 아니면 안받더라) 구조도 와닿지 않는다. keras에 익숙한 사람은 누구나 pytorch로 넘어가며 고구마 100개 순간을 경험하리라 생각해 간단한 Iris classification tutorial을 여기에 올려둔다. 구조적 특성이나 보는 관점은 전부 tensorflow에 익숙한 사람의 의견이라 처음부터 pytorch를 쓴 경우 '이 사람은 왜 이런 소리를 하나?' 생각을 할 수 있겠으나 주인장과 같은 전처를 밟은 사람이라면 이해하리라 기대한다.
Example
import torch
from torch import nn as nn
import torch.nn.functional as F
from sklearn import datasets
import numpy as np
# Define Model
class Clf(torch.nn.Module):
def __init__(self):
super(Clf, self).__init__()
self.fc1 = nn.Linear(4,10)
self.fc2 = nn.Linear(10,3)
def forward(self,x):
return self.fc2(F.relu(self.fc1(x)))
# Load Data
iris = datasets.load_iris()
X = torch.tensor(iris.data, dtype=torch.float32)
y = torch.tensor(iris.target)
# Setup Model, Optimizer, Loss function
clf = Clf()
optimizer = torch.optim.Adam(clf.parameters(), lr = 0.01)
loss_fn = nn.CrossEntropyLoss()
# Train
for _ in range(1000):
y_pred = clf(X)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(np.argmax(y_pred.detach().numpy(),1))dataset은 scikit-learn에서 들고오는 방식을 택했다. train test split, metric 등은 모두 무시하고 150개 데이터 전체를 한번에 학습시키는 단순무식한 코드임을 감안해서 보면 좋겠다.
Model
tensorflow 의 keras와 동일하게 모델을 정의하고 모델 구조를 짜서 넣어준다. 하나 차이점은 one-line으로 모델을 만들지는 못하고, nn.Module을 상속받는 class를 만들고, forward 함수를 구현해서 모델을 짜야한다는 점이다. forward 함수를 한줄로 짠 것을 보면 주인장의 귀찮음을 볼 수 있다. 모델은 별 문제없이 넘어갈 수 있다.
Data Loading
data를 넣을 때부터 슬슬 짜증이 나기 시작한다. scikit-learn에서 제공하는 iris 데이터는 numpy.ndarray 형태이다. X데이터는 float64, y데이터는 int64의 형태를 가지고 있다. 문제는 모델에서 사용한 nn.Linear가 망할 float32만 받는다는 것이다.

# Load Data
iris = datasets.load_iris()
X = torch.tensor(iris.data, dtype=torch.float32)
y = torch.tensor(iris.target)때문에 tensor로 바꿀 때 dtype 을 명시하거나 처음부터 np.astype 함수를 사용해서 float32로 바꾸어서 들고와야한다.
Model setup
loss function을 정하고 optimizer를 정하는 것은 tensorflow와 유사하다. 원하는 것을 가져다가 쓰면 된다.
한가지 유의점은 keras의 경우 model 안에 loss function과 optimizer가 같이 포함되는데 pytorch에서는 이들이 다 따로 논다.
clf = Clf()
optimizer = torch.optim.Adam(clf.parameters(), lr = 0.01)
loss_fn = nn.CrossEntropyLoss()
Training
# Train
for _ in range(1000):
y_pred = clf(X)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()tutorial의 training 파트의 코드를 볼 때는 문제가 없었는데 막상 짜다보니 멘붕이 왔다.
잠깐, 나 optimizer에 아무것도 안 넣었는데..?
clf(X) 호출을 통해서 y_pred를 구한다. foward 함수가 아마 호출이 될 것이다.
loss_fn도 이해가 된다. y_pred와 y_true(=y)를 넣어서 loss를 구한다.
optimizer.zero_grad()는 아마도 무언가 initialize를 하는 부분일 것이고,
loss.backward()는 함수명으로 보아 error를 통한 미분값을 구할 것 같은데(backward propagation) weight을 어떻게 알아서 미분값을 구하지?
심지어 loss 값은 optimizer에게 전달되지도 않았는데 혼자서 step() 함수를 호출하고 있다.
keras에서는 하나의 모델 안에 loss 함수와 optimizer가 같이 존재한다.
model = keras.Sequential(
[
keras.Input(shape=(4,)),
layers.Dense(200, activation="relu", kernel_initializer=keras.initializers.random_normal(mean=1)),
layers.Dense(200, activation="relu", kernel_initializer=keras.initializers.random_normal(mean=1)),
layers.Dense(2,name='output')
]
)
model.compile(
optimizer=keras.optimizers.SGD(learning_rate = 0.001),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.MeanSquaredError()]
)심지어 metric 함수까지 포함되어 compile 과정을 거치면 model.fit()을 호출하는 것으로 loss와 optimizer가 작동하고 metric을 알려주는 기능까지 겸하고 있다. keras는 model만 들고다니면 그 안에 모든 함수와 weight들이 묶여서 돌아다니는 구조인데 pytorch는 쉽게 납득하기 어려운 형태를 취하고 있다.
pytorch 내부를 뜯어보고 document를 뒤적이고, pytorch를 많이 쓰는 아는 동생에게 물어본 결과 겨우 작동 방식을 이해했다.
왜 이렇게 만든 것인지는 전혀 와닿지는 않지만 말이다.
먼저 gradient descent를 위해서는 세 step이 필요하다. 1) error, 혹은 loss를 계산하고, 2)이를 통해 gradient 값을 구한 뒤, 3) 일정한 learning rate을 유지하든 momentum을 더하든 실제로 weight을 수정하는 것이다.
keras의 경우 loss function은 loss를 계산하는 부분(1)만 담당하고, gradient를 구하고, 적절한 learnint rate에 맞게 수정하는 부분(2,3)은 optimizer가 담당하고 있다.
pytorch는 다르다. loss function에서 1과 2를 담당하고, optimizer가 gradient만 사용해서 실제 parameter를 수정한다.(3)
코드 실행 순서를 거꾸로 올라가면 다음과 같다.
1. optimizer가 주어진 gradient 값을 사용해서 parameter를 수정한다.
optimizer.step()optimizer가 처음 만들어졌을 때 clf.parameters()를 넣었는데, 이는 모델의 parameter를 참조하는 값이다. 때문에 optimizer는 clf 의 parameter를 수정할 수 있다. 수정에 사용하는 gradient 값은 parameter 안에 들어있다.
params = [i for i in clf.parameters()]
print(type(params[0]))
print(params[0].grad)위 코드를 실행하면 torch.nn.parameter.Parameter 형태로 clf 내부가 표현되는 것을 알 수 있으며, 이는 Tensor의 일종으로, backward 함수를 실행하면 grad 값이 생긴다. loss.backward()를 실행하지 않으면 params[0].grad는 None으로 설정되어 있을 것이다.
2. loss 값을 사용해서 gradient를 구한다.
loss.backward()그렇다면 어떻게 loss를 통해 구한 gradient가 clf의 weight까지 가는가?
loss는 Tensor type이다. 중요한 점은 이 Tensor가 단순히 data만을 담고 있지 않고, 어느 과정을 통해서 이 값들이 구해졌는지에 대한 정보를 가지고 있다는 것이다. 설마설마 하긴 했는데 이 변수 안에 어떻게 보면 이 값이 나오게 된 역사(?)가 담겨있다. (이러면 memory issue는 괜찮나...?)

tutorial에서도 제대로 알려주지 않는데 이를 확인하는 방법은 다음과 같다.
(Deep Learning with PyTorch: A 60 Minute Blitz 글 안에는 있다!)
loss.grad_fn.next_functionsTensor object인 loss에는 grad_fn이라는 필드가 있는데, 이 function 안의 next_functions field에는 이 뒤에 호출해야할 function들의 참조가 달려있다. 물론 이 순서는 해당 Tensor가 만들어진 순서의 역순이다. 이렇게 next_functions 를 따라가면 아래의 순서로 loss가 구해졌음을 알 수 있다.

때문에 loss.backward()만 호출하면 각 parameter Tensor에 grad 값이 전파된다.
각 grad_fn에 대한 자세한 설명은 공식 document에도 나와있지 않지만, AccumulateGrad가 있는 부분마다 실제 error에 의한 grad 값들이 존재하는 것으로 보인다 (각 linear layer마다 weight에 해당하는 Tensor와, bias에 해당하는 Tensor가 있을 것이다.)
3. clf를 구성하는 Tensor들의 grad 값을 초기화 한다.
optimizer.zero_grad()optimizer와 loss function이 따로 놀기 때문에 현재 parameter가 가지고 있는 gradient를 초기화 시켜주는 함수가 존재한다. 때문에 이 함수를 먼저 호출하고, 이 뒤에 loss를 backpropagation 시키는 방식으로 코드를 작성해야한다.
이 이후는 keras를 쓰던 유저도 쉽게 이해하리라 생각한다.
마치며
pytorch를 사용한 ML 논문이 이미 tensorflow를 사용한 논문의 수를 넘었다고 한다. 익숙하지 않은 구조 때문에 하루를 날리며 대체 왜 pytorch를 쓰는가에 대한 글을 찾다가 pytorch의 장점으로 동적인 computation graph를 언급하는 글을 보았다. 어쩌면 keras처럼 Model 종속적인 형태가 아니라 연산 값에 연산과정이 들어있는 구조 때문에 동적 computation graph가 가능한 것인가 하는 생각이 든다. 하나의 작은 산은 넘은 것 같다.
'취미 > Technology' 카테고리의 다른 글
| [Matlab] 2D Gaussian Convolution (0) | 2022.10.19 |
|---|---|
| Notion 입문 1달차 (0) | 2022.02.23 |
| Notion 입문 1일차 (0) | 2022.01.11 |
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
| 리튬계 베터리와 5V (0) | 2020.10.12 |
#스타트업 #힙스터 #팀워크 #생산성
스타트업'스러움'이 하나의 문화컨텐츠로 떠오르면서 온갖 제품과 서비스들이 이러한 분위기에 맞추어지고 있다. 마치 Helvetica 폰트가 디자이너들에게 사랑받기 시작하면서 세계를 장악하는 현상을 보는 것만 같다. 실제 생산성을 높이기 위함이든, 본인의 '힙함'을 보여주기 위함이든 여러 제품을 구입하고, 서비스를 구독하기 시작하면 월 구독료로 나가는 돈은 적지 않을 것이다. 또한 개중에는 이러한 문화적 흐름에 편승해서 그럴듯하게 포장한 예쁜 쓰레기를 제공해주는 곳도 많아서 사용자로 하여금 더 많은 판단을 요구한다. 자칫 생각없이 모든 것을 수용하다가는 생산성 앱으로 도배된 생산적이지 않은 본인의 기기를 보게 될 것이다.
변화에 슬슬 더디게 반응하기 시작하는듯한 기분을 떨쳐내기 위해 오래전부터 이야기를 듣고 추천을 받아온 Notion을 쓰기 시작했다. 당장에 연구실 지식베이스와 소통을 위한 목적으로 어렵게 도입했던 Slack부터 스타트업에 잠시 참여했을 때 접했던 트렐로, 2011년 1월부터 사용중인 에버노트와 iOS 한글 지원문제로 갈아탔던 OneNote까지 온갖 유사 프로그램들 접했는데 각자 지향하는 바가 분명하게 다른 것 같다. 다른 앱과 함께 하루 Notion을 써본 소감을 간략히 적는다.
* 트렐로 : 협업용 TODO 리스트
* Keep : 동기화 되는 포스트잇 게시판
* Evernote : 동기화 되는 간단한 메모장
* OneNote : 화이트보드
* Slack : 조금은 DB의 형태를 갖춘 카카오톡
* Todoist / TickTick : 혼자쓰는 TODO 리스트
Notion : 잘 정리된 Blog 글 같은 Evernote
현재 각자 사용목적성이 뚜렷하고 열심히 쓰고 있는 두 앱이 OneNote와 Evernote여서 그런지 자꾸 이 둘과 비교를 하게 된다. Evernote의 경우 기사를 대충 스크랩해서 처박아두거나, 짧은 메모, 일기 등의 줄글 위주의 게시물, 혼자 보는 용도의 설명서를 담아둔다. '동기화가 되는 간단한 메모장'이 가장 확실한 설명인 것 같다. 노트를 예쁘고 깔끔하게 만들기 위해서는 추가적으로 서식을 변경하거나 하는 등의 노력이 많이 들어간다. 그런데 그럴 일은 없다. 대충 넣어두고 나중에 필요하면 찾으면 되고, 잘 정리된 문서가 필요하면 워드로 작성하면 된다. 첫 번째 책상서랍 같은 존재다. 때문인지 유료플랜을 결제할 때는 매번 망설인다. 해주는 기능도 얼마 없으면서 이 가격을 받아야 하나 싶다.
OneNote의 경우는 아이디어 상자이다. 화면 아무 곳이나 클릭하면 바로 글이 써지고 Indent 조절이 쉽게 되고 이리저리 컨텐츠 박스를 끌고 다닐 수 있다는 점이 매력이다. 화이트보드 같은 매력이 있다. 하지만 이러한 점은 화면이 작은 모바일 기기로 볼 때 확실히 단점으로 작용한다. 화면안을 이리저리 돌아다니면서 글을 읽는 것은 정말 불편하다. 그래도 Evernote에 비해서는 깔끔한 문서정리가 가능하기 때문에 자주 꺼내보아야 하는 자료의 경우는 OneNote에 정리해서 넣어둔다.
짧은 메모, 텍스트 위주의 정보, '대충 넣어두어도 나중에 필요하면 뒤지겠지...' 하는 수준의 정보는 Evernote.
빠른 아이디어 작성, 위계관계가 확실한 정보, 조금은 정리해서 넣어두어야 하는 정보는 OneNote.
Notion은 OneNote와 Evernote 어딘가에 어중간하게 있다. 많은 사람들이 마크업 기능을 장점 중 하나로 꼽는데 확실히 여타 다른 앱들에 비해서 월등히 편리하다. 그 외에 sorting이 지원되는 깔끔한 표 삽입 기능과 댓글기능, 페이지 간 링크 등은 앞서 언급한 많은 앱들의 필수 기능들을 하나로 통합해서 왜 이런 앱이 이제야 나왔는지 싶다. 하지만 '이렇게 참신하고 대단한게 나오다니!' 보다는 '이런게 왜 이제야?'에 가깝다. 다양한 템플릿을 지원한다는 점에서는 OneNote와 가깝고 심플하다는 것에 Evernote와 비슷한 느낌을 준다. 하지만 전반적인 감상은 OneNote보다는 Evernote에 가깝다고 할까. OneNote의 '화이트보드'스러움이 있었다면 Evernote와 OneNote를 통합해서 사용할 수 있었겠으나 아이디어를 이리저리 끌고다니는 기능은 없는듯 하다. 하긴 앞서 언급한 모바일환경에서의 불편함을 생각하면 좋지 않은 방법일 수도 있겠다. Notion에서는 확실히 '협업용'의 분위기가 물씬 풍긴다. 내 난잡한 Evernote 글을 동료에게 준다면 한소리 들을 것이 분명하고, 마크업이 제대로 되지 않고 외부자료를 넣기 힘든 OneNote는 장기적인 데이터 유지 관점에서는 분명 좋지 않은 선택이다. Notion은 원활한 정보전달에 필요한 만큼의 미적 요소를 가미해서 글 작성이 가능하다. 왜 이렇게 붐을 일으켰는지 알법하다.
하지만 Notion이 얼마나 내가 쓰는 기존 프로그램들을 대체할 수 있을지는 의문이 든다. '협업'의 필요성이 크지 않기에 기존 두 프로그램들로도 충분한 목적을 달성했다. 또한 마크업 기능도 미를 위해 할애하는 시간을 해치지 않을 만큼 쉽게 되어있기는 하지만 미가 필요할 수준의 내용이면 아에 문서로 작성을 하고, 그런 것이 아니라면 짤막한 메모로도 충분하다. 그나마 이번에 진행하는 프로젝트의 일원이 Notion을 쓰는 것 같던데 이 프로젝트를 위해서 사용하는 것이라면 Notion을 충분히 쓰겠으나 OneNote나 Evernote를 내려놓기에는 조금 힘들 것 같다. 다만 메모장 프로그램에 매달 돈을 지불해야하는 점이 괘씸하기에 Evernote는 Notion로 대체를 시도하려고 한다.
'취미 > Technology' 카테고리의 다른 글
| Notion 입문 1달차 (0) | 2022.02.23 |
|---|---|
| tensorflow에서 시작하는 pytorch 작동 방식 (iris example) (0) | 2022.02.03 |
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
| 리튬계 베터리와 5V (0) | 2020.10.12 |
| HC-08 블루투스 모듈 아두이노 연결 (1) | 2018.09.09 |
어느 날부터 웹캠이 흑백으로 나온다면 아래의 방법을 시도해보자.
Microsoft 공식 홈페이지를 포함해서 대부분의 Solution들이 드라이버 업데이트/재설치, 윈도우 업데이트/재설치를 이야기 하는데 정말 간단한 문제일 수 있다.
1. 카메라 고급 옵션 접근
먼저 Skype를 실행한다. 언젠가부터 Microsoft가 Microsoft Teams랑 Skype를 쥐도 새도 모르게 깔아놓던데 아주 마음에 안든다. Skype가 깔려있지 않다면 찾아서 설치하자. 카메라 고급 옵션에 접근하는 다른 방법도 있을텐데 (video stream을 사용하는 다른 소프트웨어도 가능하지 않을까? OBS Studio 라던가) 이게 가장 간단하다.

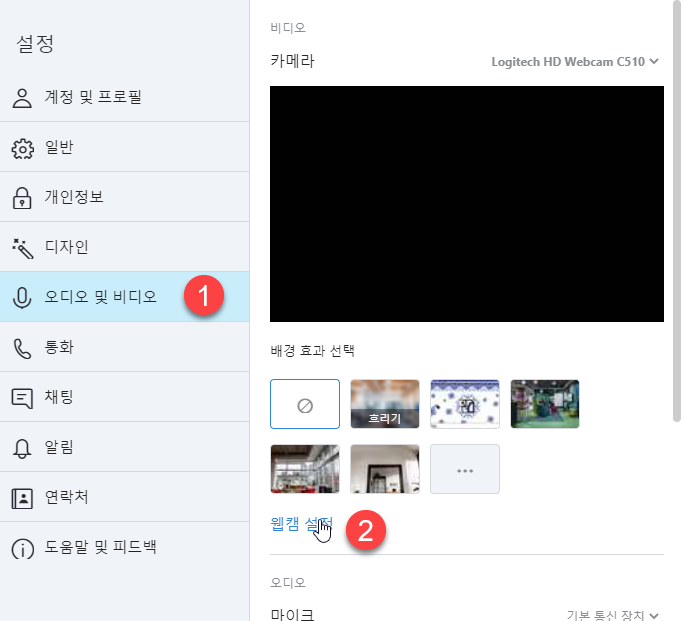
2. 카메라 고급 옵션 기본값으로 초기화.


Skype 뿐만 아니라 Zoom, Kakao Talk 등 웹캠 스트리밍이 가능한 소프트웨어에서 사용자가 직접 옵션 변경을 했거나, 낮은 조도 때문에 임의로 채도 혹은 낮은 빛 보상 옵션이 변경이 되면 흑백으로 나타나는 현상이 발생한다.
문제는 대다수의 소프트웨어들이 이러한 옵션을 display 해주지 않으며, 심지어 기준이 되어 Microsoft 기본 카메라 앱에 이 옵션에 대한 접근이 불가능 하다. (이게 주 원인인것 같다. 마소 놈들....) 심지어 한번 설정한 옵션은 카메라 모듈 내부에 따로 저장이 되는지 OS 재설치를 진행해도 흑백으로 나오는 현상이 발생한다.
삼성 노트북 A/S 후기
기술 발전과 정체로 노트북 브랜드간 격차가 사라져서 큰 차이가 없으면 국산 브랜드를 애용하자는 마음으로 현 노트북으로 삼성을 골랐다. 16Gb RAM과 외장 그래픽이 같이 딸린 200만원이 넘는 노트북 9을 구입했었는데 이게 몇 시간 Unity 기반 2D 게임을 돌렸다가 블루스크린과 함께 GPU가 저세상으로 갔다. 적어도 CPU에는 온도가 너무 높아지면 성능을 임의로 저하시켜서 칩을 보호하는 기능이 있는 것으로 아는데 이 제품의 GPU에는 이것을 제대로 구현하지 않은 것인가. 강제로 오버클럭을 시키거나 Fan이 고장났거나, 온도관련 안전장치를 해제 했으면 모르겠는데 정상 사용중 GPU가 고온으로 손상되다니 이것은 명백한 설계 미스다. 심지어 사이즈를 줄이기 위해서 CPU, RAM, GPU를 한 보드 위에 몰아두어서 GPU가 나갔다고 GPU만 고칠 수 없다더라. 수리비 90만원.
그나마 삼성에서 리퍼 부품 교환 서비스를 운영하고 있어서 절반 가격인 40만원 정도에 수리를 받았으나 제품 블랙리스트를 고려할만큼 많은 실망을 안겨주었다. A/S 기사님도 되도록 새 제품을 사는 것을 권장하셨으나 구매가를 생각하면 나쁘지 않은 선택이었다고 생각한다.
센터에 간 김에 위의 웹캠이 흑백으로 나오는 문제를 같이 문의했었다. 나는 소프트웨어 문제라고 계속 주장을 했으나 A/S 기사님이 자체 카메라 검사 유틸리티를 실행해서 확인을 했는데 진단은 카메라 모듈 하드웨어 손상. 카메라가 아예 안나왔으면 안나왔지 이런 현상을 본적이 없다고 하시더라. 카메라 모듈 역시 디스플레이와 일체형이라 수리비 20만원. 얜 포기를 하고 GPU 만 수리를 받았는데 오늘에야 문제를 자체적으로 해결했다.
노트북 제품들간 차이가 줄어든 현재, 사용자 경험의 사소한 차이가 구매로 이어진다. 수리가 어려운 구조의 제품 디자인과 GPU 보조 장치/프로그램의 설계 미스, A/S 프로토콜이 짚어내지 못한 너무나도 단순한 문제 때문에 앞으로 다른 브랜드 노트북에 눈이 가게 될 것 같다.
'취미 > Technology' 카테고리의 다른 글
| tensorflow에서 시작하는 pytorch 작동 방식 (iris example) (0) | 2022.02.03 |
|---|---|
| Notion 입문 1일차 (0) | 2022.01.11 |
| 리튬계 베터리와 5V (0) | 2020.10.12 |
| HC-08 블루투스 모듈 아두이노 연결 (1) | 2018.09.09 |
| Mendeley와 Cloud 같이 쓰기 (0) | 2018.08.24 |
장비 만드는 작업을 하다보면 리튬이온 혹은 리튬 폴리머 베터리를 이용해 5V 전원장치를 만들어 주어야 할 때가 많다.
이때 4.2V의 베터리의 전압이 정말 아쉽다.
6V 정도라면 그냥, 3V 정도 된다면 두 개를 붙여서 Voltage regulator를 연결해 5V를 끌어주면 된다.
그런데 3.7~4.2V 전압을 갖는 바람에 하나를 쓰자니 전압이 부족하고, 두 개를 붙여 8.4V로 만든 후 V reg를 연결하면 생각보다 열이 많이 나며, 전류값이 100mA만 넘어가도 방열판이 필수적이다.
이번에 아주 작은 전류만 필요한 (10mA) 장비가 있는데 DC to DC 승압 회로를 써보려고 한다.
생각해보니 AC to AC 승압/강하 회로는 트렌스포머를 쓰면 되는데 DC to DC 는 어떻게 하지 하고 찾아봤더니 코일의 역기전력을 아주 창의적인 방식으로 사용하더라.
가능하면 직접 만들어 보고 싶은데 일단 그전에 MOSFET 작동방식부터 파악을 하고 와야겠다.
'취미 > Technology' 카테고리의 다른 글
| Notion 입문 1일차 (0) | 2022.01.11 |
|---|---|
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
| HC-08 블루투스 모듈 아두이노 연결 (1) | 2018.09.09 |
| Mendeley와 Cloud 같이 쓰기 (0) | 2018.08.24 |
| 로지텍 헤드셋 G633 리뷰 및 수리기 (17) | 2018.08.05 |
IoT를 이용하는 전등 스위치를 동생 생일 선물 대신 만들어주기로 하였다.
기존에 파는 제품들도 있으나 가격도 비싸고 기능도 별로 없는듯 하여 직접 제작에 들어갔다.
컨트롤러야 아두이노 나노를 쓰면 되고, 전등은 100V 이상의 고압을 사용하니 릴레이로 컨트롤,
문제는 무선 방식을 택했기에 Wifi든 Bluetooth든 지그비 통신이든 통신 모듈을 아두이노와 연결해야했다.
통신거리가 길어봐야 수m 이고 Bluetooth라면 시리얼 통신 앱이 어떤 OS든 하나는 있을 것 같았기에 Bluetooth 로 개발을 하기로 결정.
전기회로를 설계할 때 가능하면 중국제 제품을 안쓰려고 하는데, 품질이 의심되기 보다는 주로 datasheet를 찾기 어렵거나, 있다고 해도 중국어로만 되어 있는 경우가 간간히 있어서 그렇다.
가격을 생각해서 Devicemart에서 중국제 HC-08 Bluetooth 모듈을 일단 구매 했으나, 다양한 제품들을 만드는 회사라 검색어 오염이 있고, 다른 제품군에 대한 설명은 많으나 HC-08 제품에 대한 설명은 거의 전무했다.
다른 제품들과 중국어로된 회사 홈페이지를 뒤져서 결국 통신에 성공했다.
Bluetooth 모듈 사용은 이번이 처음이기에 연결을 시키면서 다양한 것을 배웠다.

1. Arduino와 HC-08의 연결
일단 부품은 잘 모르면 무조건 모듈로 된 제품을 사야한다.
그냥 덜렁 센서만 툭 샀다가 어떻게 연결하는지도 모르고 고생하기 쉽다.
생으로된 HC-08 모듈을 구매하고 길을 찾고자 여기로 오신 분은 얼른 가서 모듈로된 부품을 구매하기 바란다.
하지만 안타깝게도 부품을 구매한 Devicemart에도 제대로된 모듈 연결방법 설명이 없었다.
연결방법은 간단하다. 핀은 총 6개가 나와있는데 실질적으로 4개만 사용하면 된다.
* Serial 통신
거의 대부분의 Serial 통신, 직렬 통신은 핀이 네개 필요하다.
VCC, GND, TX, RX
VCC와 GND는 말 그대로 전극의 +와 -. 장치에 전력을 공급해주는 핀이다.
나머지 둘이 통신을 위해서 필요한 핀인데, TX는 데이터 전송용, RX는 데이터 수신용으로 필요하다.
중요한 것은 두 장치를 서로 연결할때 VCC와 GND는 극성 잘 보고 꼽으면 되지만 RX와 TX는 정 반대로 연결을 해주어야 한다는 것이다.
VCC핀은 보드의 5V 핀에 그대로 연결. GND 핀도 보드의 GND 핀에 그대로 연결을 하면 되지만,
통신 모듈의 RX핀은 보드의 TX 핀에,
통신 모듈의 TX핀은 보드의 RX 핀에 연결을 해주어야 한다.
Arduino 보드에도 Digital 0번, 1번 핀이 이러한 기능을 수행해 주는데, 이경우 아두이노인지 블루투스 모듈인지 둘중에 하나와 통신이 안되었던 것으로 기억한다.
아, 아마 아두이노의 Serial Monitor 창에서 입력하는 값이 TX가 안되었던 것 같은데...
여튼 아두이노의 D0 D1핀은 앵간하면 건드리지 않는 것이 좋다는게 경험이다.
문제는 그럼 어떻게 Serial 통신을 하느냐, 아두이노 자체적으로 있는 라이브러리인 <SoftwareSerial.h>를 사용하면 된다.
이 라이브러리를 사용하면 지정한 디지털 핀을 TX와 RX 핀으로 설정해서 Serial 통신을 가능하게 해준다.
최종적으로 연결은 이런식으로 하면 됩니다.



VCC와 GND는 알아서들 잘 연결하실꺼고,
위의 사진에서 모듈의 RX는 아두이노의 D10에, TX는 D11에 연결을 했다.
2. AT(필드) 코드
이번에 처음 배운 것이다.
왜 어디에도 AT 코드를 설정하는 방법에 대해서 나와있지 않는가....
either 너무 기본적인것이거나 다들 불친절한 것이거나.
AT 코드는 Serial 통신을 사용해서 모듈의 칩의 설정을 바꾸어 주는 코드이다.
이 블루투스 모듈에선는 아래의 AT 코드들이 있다.

펌웨어 버전 확인부터, 블루투스 이름 변경, 연결가능성 설정 등의 메뉴가 있다.
문제는.... 이 코드를 그래서 어디에 어떻게 입력하는지 몰랐다.
설마 그냥 Serial 통신을 연결해두고 "AT"라고 정말 입력하면 돼??
사전 준비가 조금 필요하지만 일단은 진짜 문자 그대로(= ASCII 코드로 ) 저 코멘드를 입력하면 되더라.
일단 HC-08 모듈은 조금 특수적으로 AT Mode에 들어가야 저 명령어가 먹는다.

HC-08아닌 다른 모듈의 경우 KEY를 누르거나 5V 전압을 인가하면 된다고 하던데 그냥 전원을 넣은 상태로 다른 기기와 Pairing이 안된 상태면 무조건 AT 모드에 있는 것 같다.
참고로 이때 이 모듈의 경우 LED가 깜박거린다.
AT 모드에 진입한후 저 명령어를 입력하기 위해서는 아래의 코드가 필요하다.
3. 소프트웨어 제작
#include <SoftwareSerial.h> // 가상 Serial 통신을 위해 헤더파일 불러오기
byte rxPin = 11; // 모듈에서의 RX는 D10번, TX는 D11에 넣었다.
byte txPin = 10; // 그렇기에 모듈의 RX와 연결된 D10번 핀은 TX핀으로 설정해야한다.
// 참고로 사용하는 아두이노 기종에 따라서 SoftwareSerial.h를 사용할 수 없는 핀들이 존재한다.
// 꼭 홈페이지에서 document를 읽고 오자.
// Uno 기준으로는 10번, 11번 모두 해당이 없다.
SoftwareSerial BT(rxPin, txPin); // BT 라는 이름으로 설정.
char c = ' ';
void setup() { // 두 시리얼 포트를 모두 시작.
Serial.begin(9600); // 시리얼 모니터용
BT.begin(9600); // 블루투스 모듈용
}
void loop() {
if(BT.available()){ // BT 모듈에서 응답을 받는 경우이다. BT의 TX에서 전송이 들어올 때.
while(BT.available()){ // while문을 넣지 않으면 한줄에 한글자씩 출력된다.
delay(10);
c = BT.read();
Serial.print(c);
}
Serial.println("");
}
if(Serial.available()){ // Serial 모니터에서 직접 값을 입력한 경우.
c = Serial.read();
BT.write(c); // 블루투스 모듈의 RX 핀으로 쏴준다.
}
}
char 형식이 아니라 16진수 그대로 출력하게 해두고 가지고 놀다가 재미있는 사실을 발견했는데 값이 입력될때 내가 입력한 문자의 아스키 코드 뿐만 아니라 10진수로 10, 13 이 같이 입력이 되는 현상을 발견했다.
찾아보니 각각 Line Feed와 Carriage Return.
아무래도 시리얼 모니터에 값을 입력하고 엔터를 눌러 전송을 하면 엔터 값 자체도 전송이 되는 듯 하다. (이것도 기본적인 거겠지만 이번에 처음 배웠다.)


참고로 해당 설정은 시리얼 모니터의 아래에서 바꿀 수 있다.
3-1. (baud rate을 모르는 경우)
다른 사람이 baud rate을 변경해놓고 사라지거나, 이전에 바꾼 값이 기억이 안나는 경우 통신이 안되어 당황하게 되는 경우가 있다. 그 때에는 아래의 코드를 사용하자.
9개의 baud rate 값들에 대해서 각각 테스트 한 뒤, response가 오는 경우 OK 라고 뜰 것이다.
#include <SoftwareSerial.h>
byte rxPin = 11;
byte txPin = 10;
SoftwareSerial BT(rxPin, txPin);
void setup() {
Serial.begin(9600); // 시리얼 모니터용
Serial.println();
long btr[9] = {4800, 9600, 19200, 31250, 38400, 57600, 74880, 115200, 230400};
for (int i = 0; i<9; i++){
BT.begin(btr[i]);
Serial.print("Testing baud rate: ");
Serial.println(btr[i]);
delay(10);
BT.write("AT");
delay(1000);
if(BT.available()){
while(BT.available()){
delay(10);
c = BT.read();
Serial.print(c);
}
Serial.println("");
}
}
BT.end();
}
void loop() {
}
4. 연결
아두이노 연결과 모듈 연결을 성공적으로 끝냈으면 위의 코드를 올리고 시리얼 모니터에
AT
라고 입력을 하면
OK
라고 뜨는 것을 확인할 수 있다.
(참고로 엔터를 눌러서 값을 전달하는 것과 전송 버튼을 눌러 값을 전달하는 것은 값이 다르다.)
두 HC-08 모듈을 연결하기 위해서는 하나는 마스터 모드, 하나는 슬레이브 모드여야 가능하다.
지그비 통신에서도 비슷한 것을 본 적이 있는데 여기서도 그렇게 작동하나 보다.
둘다 AT 모드에서 설정을 바꾸지 않았다면 둘다 Slave 로 되어 있을 것이다.
AT+ROLE=M
커멘드를 입력하고
AT+RX 커멘드를 통해서 위의 시리얼 모니터처럼 값이 나오는지 확인한다.
Role : Master
라고 나올 것이다.
자... 이제 두 모듈을 어떻게 서로 연결해주지....
했는데 그냥 연결이 알아서 되더라.
여러 모듈이 동시에 존재하는 경우에는 어떻게 해야하는지는 모르겠으나, 같은 공간에 마스터 하나와 슬레이브 하나만 존재하고, 거리가 멀지 않으면(10미터 이하) 즉각 둘이 페어링이 되는 듯 하다.
일단 목적은 두 기기를 연결시키는 것이라 여러 모듈을 서로 연결시키는 것은 시도해보지 않았다.
나와 같이 HC-08을 사고 힘들어하는 누군가에게 도움이 되었기를 바라며...
'취미 > Technology' 카테고리의 다른 글
| 웹캠이 흑백으로 나와요. 해결방법(feat. 뒤늦은 삼성 노트북 A/S 후기) (3) | 2021.08.19 |
|---|---|
| 리튬계 베터리와 5V (0) | 2020.10.12 |
| Mendeley와 Cloud 같이 쓰기 (0) | 2018.08.24 |
| 로지텍 헤드셋 G633 리뷰 및 수리기 (17) | 2018.08.05 |
| 크레마 카르타 (1) | 2018.06.03 |
서지 관리 프로그램으로 EndNote를 써봤지만 왜인지 모르게 입맛에 맞지 않았고 Mendeley로 갈아탄지 2년.
본인은 데이터를 전부 개인 NAS에 올려서 보관을 하고 있기에 찾은 논문들도 클라우드에 올라가 있다.
Mendeley에 있는 유용한 기능 셋을 나열하자면,
- 클라우드 기능. 찾은 PDF를 자체 cloud에 업로드/다운로드 할 수 있다
- watched folder 기능. 폴더 하나를 지정하면 해당 폴더에 들어오는 새로운 pdf 파일을 인식해서 자동으로 등록해준다.
- organize 기능. 찾은 pdf를 하나의 폴더에 넣어준다.
목적은 단순했다.
기존의 PDF 파일들을 동기화 하던 방식(자체 NAS)을 유지하면서 Mendeley를 쓰고 싶었다.
개중에는 비슷한 연구자가 또 있을거라 생각한다.
원래 드랍박스나 OneDrive로 논문을 관리하다가 Mendeley를 쓰게 되는 경우처럼.
Mendeley의 클라우드를 쓰기 싫은 이유는
1. 내 NAS가 더 빠르다.
2. 거지같은 아이패드에서 쓰는 pdf 앱은 Mendeley의 cloud에는 접근하지 못한다.
물론 iOS용 Mendeley 앱이 있으나 자기네 클라우드에서 파일을 받는 것만 가능한 것으로 앎.
왜냐하면 Mendeley 앱에서 pdf를 받고 그걸 내가 쓰는 pdf 리더 앱으로 열고 수정한 다음에 닫으면 그게 Mendeley로 넘어가지 않아서 서버로 올려주지 못하거든.
물론 Mendeley 앱 내의 주석기능으로 수정하면 반영이 된 상태로 다시 업로드가 되지만.
3. 안에서 폴더를 나눠도 실제 파일 시스템에서는 폴더가 나뉘지 않는다.
결론적으로
"내 PDF는 알아서 내가 관리할테니 Mendeley 너는 목차나 잘 만들고 비슷한 논문 뜨면 찾아줘"
문제는....
Mendeley 자체적으로 cloud 기능이 있기에
1. 새로운 장치에 mendeley를 설치한다.
2. 폴더를 자체적으로 만들고 Mendeley 클라우드에서 pdf 파일들을 다 내려받는다.
(이 pdf 파일들은 사실 이미 내 클라우드의 논문 폴더에 다 들어가 있다.)
Case A. Mendeley에서 pdf를 열고 수정할 경우 자체 폴더에 있는 pdf가 수정되고 내 클라우드에 있는 친구들은 수정이 안된다.
Case B. Mendeley에서 pdf를 열지 않고 클라우드에서 열어서 수정할 경우 Mendeley 앱에서 열었을 때 수정이 안된 버전이 보여진다.
온갖짓을 다 해봤는데 결국 안되는듯 하다.
누가 멋대로 pdf 파일 가져가래.. PDF 동기화를 끄는 버튼도 없다.
물론 한 컴퓨터를 정해서 지속적으로 Cloud 논문 파일을 Mendeley에 업로드 해주면서 다른 모든 기기에선 Mendeley 클라우드를 이용하는 방법도 있긴 하다. 귀찮아서 그렇지... 마치 pull이 한 컴퓨터에서만 되는 git의 느낌이려나.
'취미 > Technology' 카테고리의 다른 글
| 리튬계 베터리와 5V (0) | 2020.10.12 |
|---|---|
| HC-08 블루투스 모듈 아두이노 연결 (1) | 2018.09.09 |
| 로지텍 헤드셋 G633 리뷰 및 수리기 (17) | 2018.08.05 |
| 크레마 카르타 (1) | 2018.06.03 |
| 당신이 탈착형 배터리 형태의 핸드폰을 써야하는 7가지 이유 (0) | 2016.09.08 |
때는 작년 여름, 모종의 이유로 MMORPG를 본의아니게 시작하게 되었다.
같은 모종의 이유로 길드에 가입하게 되었는데 같이 던전을 돌거나 잡담을 하기 위해서는 디스코드를 필수로 사용해야했고, 마이크가 달린 헤드셋의 필요성이 생겼다.
이전에는 마이크가 달린 이어폰을 사용했었으나 핸드폰으로 계속 디스코드를 틀어놓기에는 한계가 있었기에..
처음으로 특정 품목의 상품을 구입하면, 특히 전자기기인 경우, 가장 비싸고 좋은 제품부터 시작해서 필요 없는 기능을 뺴면서 하위 기종으로 내려오는 경향이 있는데 이번에도 같은 방법으로 헤드셋을 알아보았다.
로지텍 제품을 벌써 4개나 구입하고 주변 사람들에게 3개를 더 판 로지텍 빠이기에 로지텍 게이밍 기어를 둘러보다가 마음에 드는 제품으로 G633 기종을 골랐다.

<https://www.logitechg.com/>
(그때는 G933이 없었던것 같은데.. )
구입 당시로부터 거의 1년이 지났는데 아직도 G633이 가장 최신 기종 라인으로 나와있다.
G933과의 차이점은 무선이냐 아니냐의 여부인 것으로 보인다.
그때도 G933이 있었는지는 기억이 나질 않는데 아마 있었다면 무선이 편하기는 하는데 선 정리만 잘하면 굳이 무선 기능을 쓸 이유가 없을듯 해서 + 괜한 딜레이 걱정 때문에 G633을 구입하지 않았을까 생각한다.
개봉기가 아니라 구입후 1년동안 쓴 후기, 제대로 된 리뷰를 시작합니다.
1. 사운드 : 하상 (가격에는 못미침)
안타깝게도 필자는 소위 '막귀'인 사람인지라 가격차이가 4~50만원씩 차이가 나지 않는 이상 오디오 제품의 성능을 구별하지 못한다. 해봐야 상중하로 구분할 수 있으려나.
하지만 G633은 18만원이라는 가격의 오디오 제품에 기대하는 성능 이하의 사운드를 보여주었다. 마이크와 기타 기능들이 달려있는 제품이기에 18만원이라는 가격이 나왔는지는 모르겠지만 음악 감상용의 18만원대 헤드폰에 비해서는 확실히 낮은 품질이었다.
어쩌면 게이밍 헤드셋과 음악 감상용 헤드폰을 1:1로 비교하는 것은 반칙인것 같지만 로지텍사에서 가장 비싼 라인으로 나와있는 헤드폰인데 가격을 더 높이더라도 사운드에 신경을 더 쓸 수 있지는 않았을까.
2. 기능 : 최상
가장 마음에 드는 기능은 접이식 마이크이다.
마이크 부품에 스위치가 있어서 마이크를 올리고 내리는 동작으로 시스템적으로 마이크를 껐다 켰다 할 수 있다. 또한 멀티 플레이 게임중에 다른 사람들이 말해준 바로는 내 마이크에서 다른 잡음이 상대적으로 덜 들린다고 하더라.
좌측 스피커 옆에 붙어있는 볼륨조절 버튼이나 기타 기능들도 유용하게 쓸 수 있을 것 같다.

<https://www.logitechg.com/>
눌러서 말하기 기능으로 쓰기에는 매번 헤드셋으로 손을 올리기 어려워서 사용하기 어려웠다.
하지만 직관적으로 사운드를 조절하거나 뮤트 버튼 등을 배정시켜서 편리하게 사용하고 있다.
로지텍 게이밍 기어 제품을 하나 이상 가지고 있다면 같은 프로그램으로 키 변경이나 EQ 등 잡다한 설정들을 변경할 수 있다.
참고로 난 제발 게이밍 기어에 색 좀 넣지 말았으면.. 컬러 LED 왜 넣는 거임...
커스터마이즈를 통해 뭔가 돋보이고 싶어하는건 알겠는데 이런거 커스터마이즈 할 시간에 얼굴을 커스터마이즈 해라
사진 맨 위에 보면 03 버튼 위에 파란색이 살짝 보이는 토글 버튼이 보인다.
헤드폰에 USB 선, AUX 선을 두개를 꼽을 수 있는데 USB 선으로는 컴퓨터와 다이렉트하게 연결이 되고 AUX 선을 사용하면 핸드폰이나 다른 음향기기와 직접적으로 연결할 수 있다.
믹싱 기능은 당연히 없고 저 토클 버튼을 사용해서 어디로부터 입력을 받을까를 결정할 수 있다.
컴퓨터와 피아노에 연결해두고 음악 제작 작업을 해본적이 있는데 Ground 선이 서로 붙어있는지 AUX로 설정해두고 피아노를 치니 노이즈가 끼더라. 꺼진 컴퓨터에 연결되어있던 USB 선을 뽑았더니 노이즈가 사라지는 것을 확인했다. 이 부분에 있어서는 살짝 디테일이 부족한 것은 아닐까 싶다.
3. 내구도 : 최악
이 글을 쓴 이유이기도 하다. 내구도가 엉망이다.
이어폰을 사용하는 사람들이 단선을 가장 걱정한다면, 헤드셋을 사용하는 사람들은 헤드셋의 목이 잘리는 현상을 가장 걱정한다.

이 빨간 부분이 끊어지는 현상. 헤드폰 부품중에서 가장 큰 압력이 걸리는 부분이기에 단단하게 만들어야 한다. <http://mofi.co.kr/>
이어폰 단선이나 헤드셋 목잘림이 그렇게 자주 있는 일은 아니지만, 가장 취약한 부분이기에 한번 크게 사고가 나거나 3년 이상 오래 쓰면 아무리 조심히 써도 신경을 쓰게 되는 부분이라고 생각한다.
필자도 젠하이저 접이식 헤드폰을 선물받아서 매일 사용하다가 1년을 못견디고 저 부분이 부러지는 사건이 두번이나 있었다.
이후에 출시된 후속작에서는 해당 부분을 메탈 재질로 바꾸어서 출시했다.
그럼 G633 제품은?
금속 부품 하나 없이 전부 플라스틱 재질이다.
헤드셋의 아치 부분 안에는 메탈이 들어가 있지만 나사를 제외하곤 모두 플라스틱으로 만들어졌다.
그래서 무슨 일이 벌어졌느냐...

처음에 제품을 사서 착용할 때부터 플라스틱이 서로 부딪혀서 끼이익 거리는 소리가 나는 것이 내구도의 허접함을 소리치고 있었는데 결국 이런 일이 벌어졌다.
저 부품 하나가 헤드셋 한쪽에 가해지는 압력을 모조리 받고 있는데 끊어진 부분 두께가 1.5mm 이다.
세상에 이쑤시개 여러개를 동그랗게 말아서 쓰는 것이 더 튼튼하겠다
로지텍사에 연락을 했으나 타 블로그에서 외국인 리뷰어가 심하게 까는 것 처럼 서비스를 안해준다더라.
순간접착제로 부품을 붙여보거나 글루건으로 떨어진 부분을 통쨰로 접합하거나 했지만 역시나 압력이 크게 가해져서 1시간만에 떨어져나갔다.
여기서 부터 수리기.
결국 일을 크게 벌렸다.
망할놈들이 안고쳐준다면 내가 부품을 하나 만들고 말지...
부서진 부품을 역설계 해서 3d 모델을 만들고 단선 없이도 부품을 선에 결착할 수 있도록 디자인을 수정했다.



처음에는 위파트 아래파트 만들어 선 위에서 붙이려 했으나 어려웠다.
결국 저렇게 단일 부품 구조로 엇갈린 형태의 홈을 만들어 선을 저 사이에 억지로 끼워넣도록 했다.



기어이 완성.
중간에 원래 붙어있던 부품을 빼낼때 니퍼로 조금씩 부수며 빼다가 선을 끊어먹을 뻔 했다...
다행히 기능에는 지장이 없는 것으로 봐서 선 겉의 피복만 끊어버린 것 같다.
이번 리뷰 및 수리기의 결론
1. 헤드셋을 살 때 가격 이전에 저 연결부가 충분히 두꺼운지, 혹은 플라스틱이 아니라 금속을 사용했는지를 꼭 확인하자.
2. 로지텍 개쓰레기(하지만 계속 쓰긴 할 것 같다. A/S 제대로 해주는 업체가 삼성 엘지 말고 어디있어. 대신 비싼 제품은 이제는 못살듯 싶다.)
'취미 > Technology' 카테고리의 다른 글
| 리튬계 베터리와 5V (0) | 2020.10.12 |
|---|---|
| HC-08 블루투스 모듈 아두이노 연결 (1) | 2018.09.09 |
| Mendeley와 Cloud 같이 쓰기 (0) | 2018.08.24 |
| 크레마 카르타 (1) | 2018.06.03 |
| 당신이 탈착형 배터리 형태의 핸드폰을 써야하는 7가지 이유 (0) | 2016.09.08 |